When Observability Spend Runs Away: Metrics, Cardinality, and SaaS Billing Surprises
Nina · April 20, 2026
Logs, traces, and metrics power reliability—but SaaS-based observability bills can spike overnight. Learn how engineering and FinOps should govern ingestion, sampling, retention, and vendor pricing models together.
Engineering leaders celebrate shipping features; finance notices when the observability invoice doubles after a busy launch. Modern SaaS monitoring platforms price on ingestion volume, host counts, retained cardinality, or seats—sometimes all at once. A single misconfigured exporter can flood metrics with unbounded label combinations, turning a reliability investment into a budget crisis. Governance here is not about stifling visibility; it is about aligning telemetry value with cost and reliability goals so incidents are still diagnosable without paying to store noise forever.
Understand pricing physics
Cardinality drives cost in many metrics backends—each unique combination of labels creates storage and query load. Traces amplify expenses when sampling is disabled during spikes. Logs become expensive when debug verbosity ships to production by mistake. Read vendor pricing guides with engineering leads, translating abstract “per million spans” into scenarios your systems actually produce. Build rough models for peak events: Black Friday, quarter-close batch jobs, or incident storms.
Separate environments. Development clusters should not inherit production retention policies or export volumes. Namespace isolation prevents test harnesses from polluting billing and obscuring real anomalies.
Operational guardrails
Implement review processes for new instrumentation: required labels, forbidden high-cardinality fields (raw user IDs in unrestricted tags), and approval for custom dashboards that query huge windows. Automate alerts when ingest rates exceed baselines; often the first signal is finance’s email, which arrives too late.
Sampling strategies should be explicit defaults, not tribal knowledge. Tail-based sampling for traces and dynamic sampling for logs preserve signal during incidents while compressing steady-state cost. Document runbooks for temporarily increasing verbosity during investigations—and turning it back down.
FinOps and engineering partnership
Embed observability spend in engineering OKRs alongside uptime. When teams own both, they optimize holistically. Finance should attend quarterly architecture reviews for platforms exceeding materiality thresholds—not to veto tooling, but to understand trade-offs when evaluating alternatives.
- Chargeback signals — Show teams their portion of observability bills tied to services they control.
- Benchmarks — Compare cost per transaction or per active user across product lines to spot outliers.
- Contract design — Negotiate burst allowances and true-up fairness for telemetry-heavy quarters.
Tool sprawl considerations
Organizations often accumulate overlapping SaaS monitoring products after acquisitions or team preferences. Rationalize slowly with evidence: overlapping coverage, alert fatigue, and duplicated ingestion. Sudden mandates to “pick one tool tomorrow” harm reliability. Instead, sunset redundant paths with migration timelines tied to incident readiness checkpoints.
Retention versus investigability
Long retention feels safer until bills and query latency explode. Tier retention by signal type: keep error logs longer than debug noise; store exemplar traces instead of complete populations for steady state. Align vendor retention settings with internal policy and regulatory minimums—over-retention increases breach blast radius as well as cost.
Test restore and query performance quarterly. Some teams discover they cannot replay incidents beyond thirty days because dashboards time out even though data technically exists. Performance engineering is part of observability economics.
Incident response and cost spikes
During major outages, engineers naturally increase verbosity. Pre-authorize temporary budget envelopes for incident ingestion so teams do not hesitate to instrument while customers are impacted. After resolution, require a post-incident cost review: which verbosity changes were reverted, which dashboards should be deleted, and whether permanent sampling rules need updates.
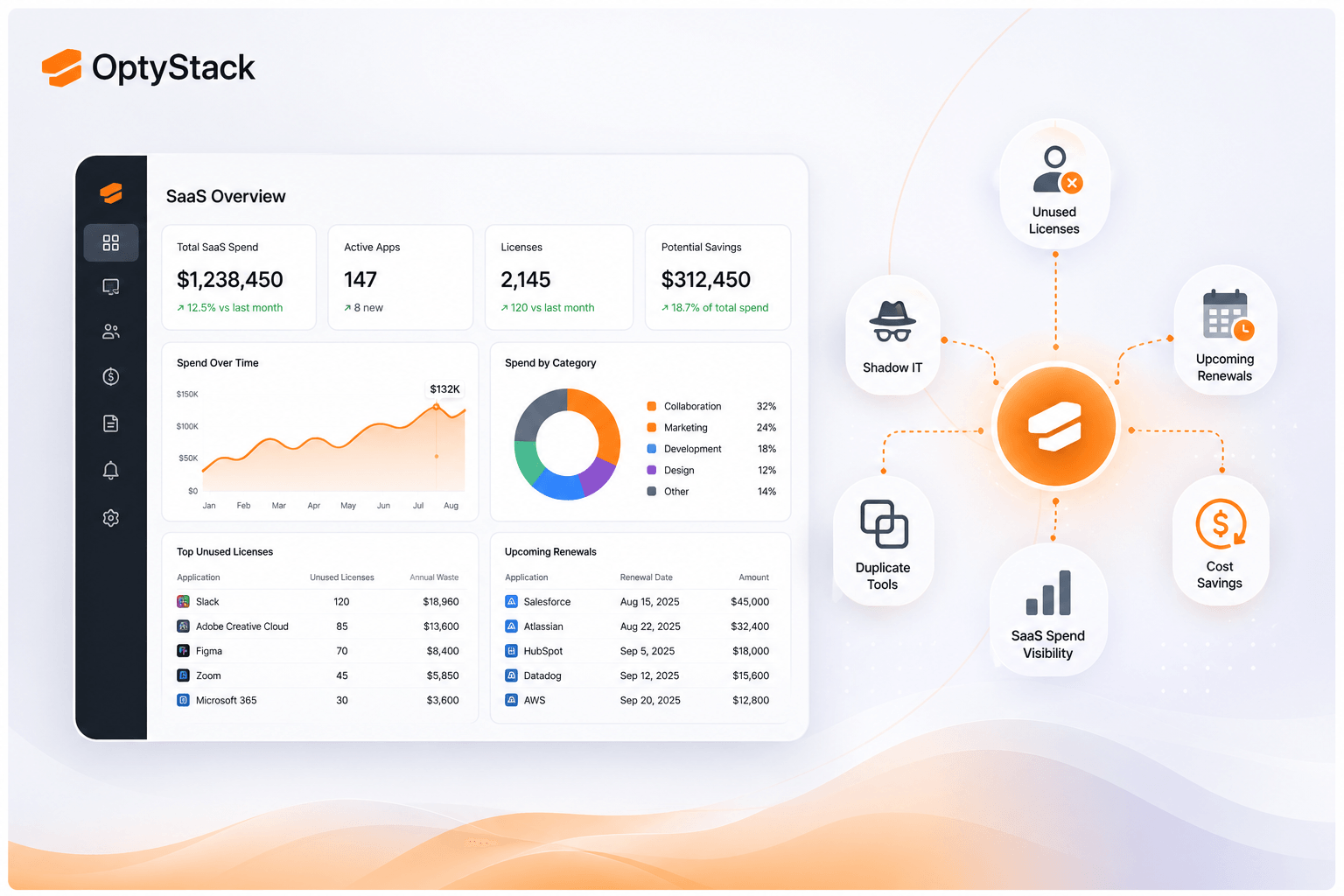
OptyStack’s lens on SaaS adoption helps FinOps and platform engineering see which observability vendors are active, who owns contracts, and where duplicate capabilities inflate spend. That visibility supports consolidation without guessing from invoice lines alone.
Culture of observability economics
Train engineers that telemetry is a product feature with costs, not free infrastructure. Celebrate teams that refactor noisy metrics and penalize repeated incidents caused by blind spots created by excessive cost cutting—balance matters. Executive support is essential when short-term savings pressure conflicts with long-term diagnosability.
Observability should make systems understandable; billing surprises undermine that clarity. Govern ingestion with the same rigor you apply to production code, and your reliability stack remains both trustworthy and affordable.
Vendor evaluation and proof-of-value
Before committing to multi-year observability contracts, run controlled proofs that measure ingest efficiency, query latency at your expected cardinality, and support responsiveness during simulated incidents. Pricing calculators are optimistic; your workloads are not. Document acceptance criteria so procurement can enforce credits if reality diverges from demos.
Consider interoperability: exporting metrics and traces to cheaper long-term stores may suit compliance archives while SaaS handles interactive investigation. Hybrid patterns reduce lock-in and smooth bill volatility.
Security and privacy of telemetry
Logs and traces often contain PII and secrets. Scrubbing pipelines belong in architecture reviews alongside cost reviews—data minimization improves both privacy posture and bills. Align redaction rules with legal retention mandates so engineering does not oscillate between over-collection and under-investigation.
Making observability cost a first-class SRE concern
Embed cost checkpoints into service readiness reviews alongside latency and error budgets. Services should declare expected telemetry volumes and cardinality budgets the same way they declare SLOs. Violations trigger architecture conversations before bills spike.
Run game days that include observability failure modes: what happens if the vendor throttles ingestion during an incident? Practice failover to secondary sinks or cached dashboards. Resilience planning without telemetry contingencies is incomplete.
Share anonymized per-team telemetry spend league tables internally—framed as engineering excellence, not shame. Teams learn from each other’s sampling strategies when data is visible.
Partner with FinOps to include observability in capital versus OpEx discussions where long-term commits apply; sometimes annualizing spend clarifies trade-offs against building internal sinks.
Governance dashboards engineering and finance share
Build unified dashboards showing ingest volume, cardinality growth, top noisy services, and projected bill impact. Shared vocabulary prevents “engineering surprise” and “finance nagging.” Review dashboards in joint monthly forums with action items, not passive viewing.
Tie dashboard thresholds to budgets: when projections exceed quarterly envelopes, trigger automatic architecture reviews—not finger-pointing emails. Predictability beats heroics.
Archive dashboard snapshots during major releases to correlate feature launches with telemetry changes; causality becomes obvious instead of debated.
Closing thoughts
Observability economics ties reliability to financial sustainability: cardinality budgets, sampling defaults, retention tiers, and incident verbosity policies belong in the same governance family as SLOs. Finance and engineering should share dashboards, budgets, and vocabulary; surprises help nobody. Evaluate vendors with proofs, not slides; scrub sensitive data to protect privacy and bills; plan game days for telemetry failures. Consolidate redundant SaaS tools deliberately, and treat cost reviews as part of incident retrospectives. Mature organizations know what they ingest, why they ingest it, and what they are willing to pay for the next outage—before the invoice proves they did not.
Encourage service owners to annotate runbooks with “telemetry expectations”—expected log volume, mandatory labels, and sampling toggles—so new engineers inherit good habits instead of rediscovering painful lessons.
When evaluating open-source or self-hosted alternatives, include fully loaded engineering hours; sometimes SaaS remains cheaper when labor is honest.
Establish quarterly “telemetry budget” reviews alongside infrastructure capacity planning; treat spikes as capacity signals, not one-off miracles.
Reward reductions in noisy metrics with the same enthusiasm as latency wins—both improve customer experience and sleep schedules for on-call engineers.
Include observability spend in developer productivity metrics dashboards so platform teams see cost and velocity together.
When budgets tighten, avoid blind cuts—prioritize retention reductions and sampling tweaks before deleting signals that shorten incidents.
Document vendor account team contacts next to billing IDs so cost questions route quickly during month-end closes.